Validating Bets
Finding what exactly to focus on
We clearly needed a separate database where recruiters could park good talent. While this exists in other tools, we needed to validate our specific approach. We broke the hypothesis down into 6 core bets:
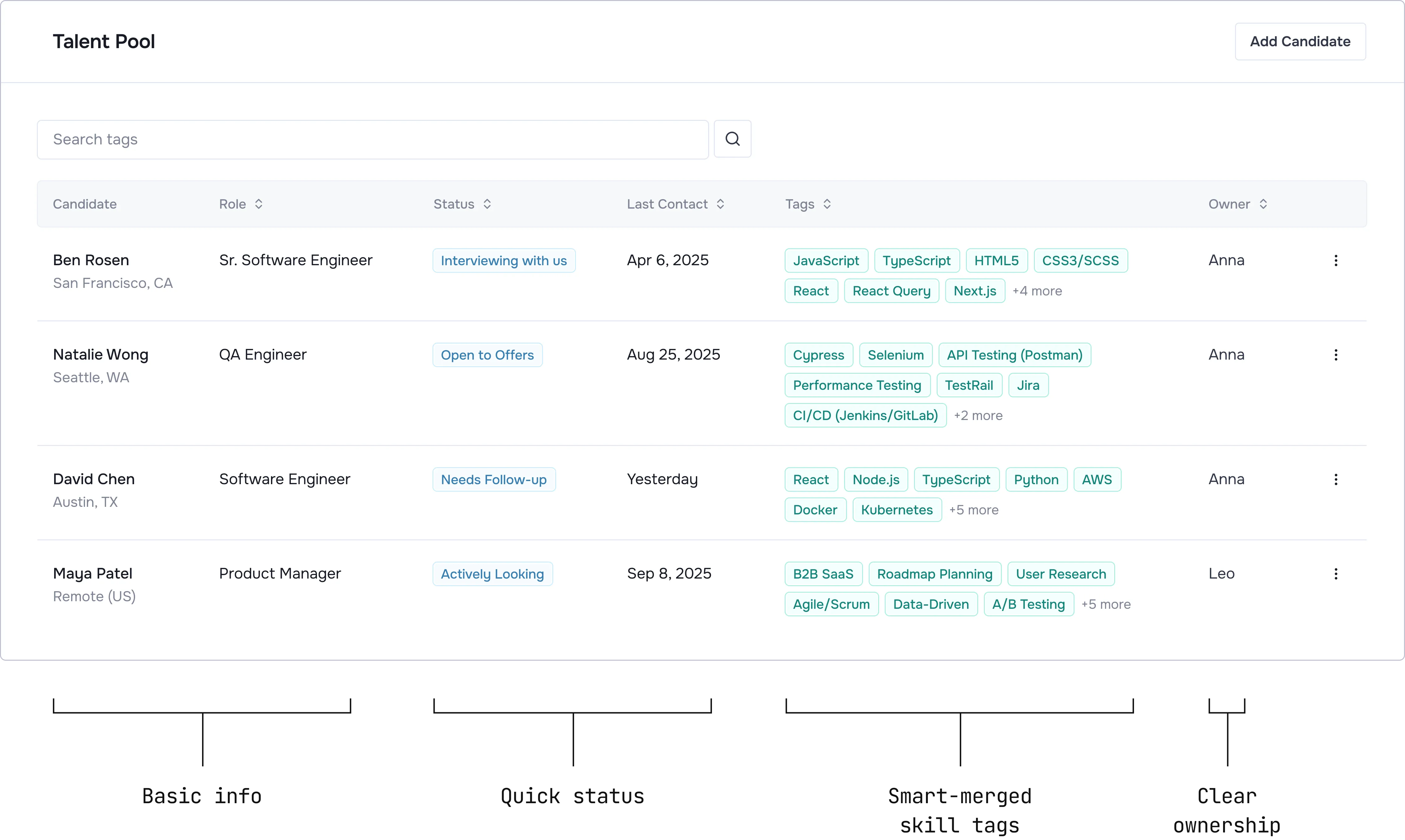
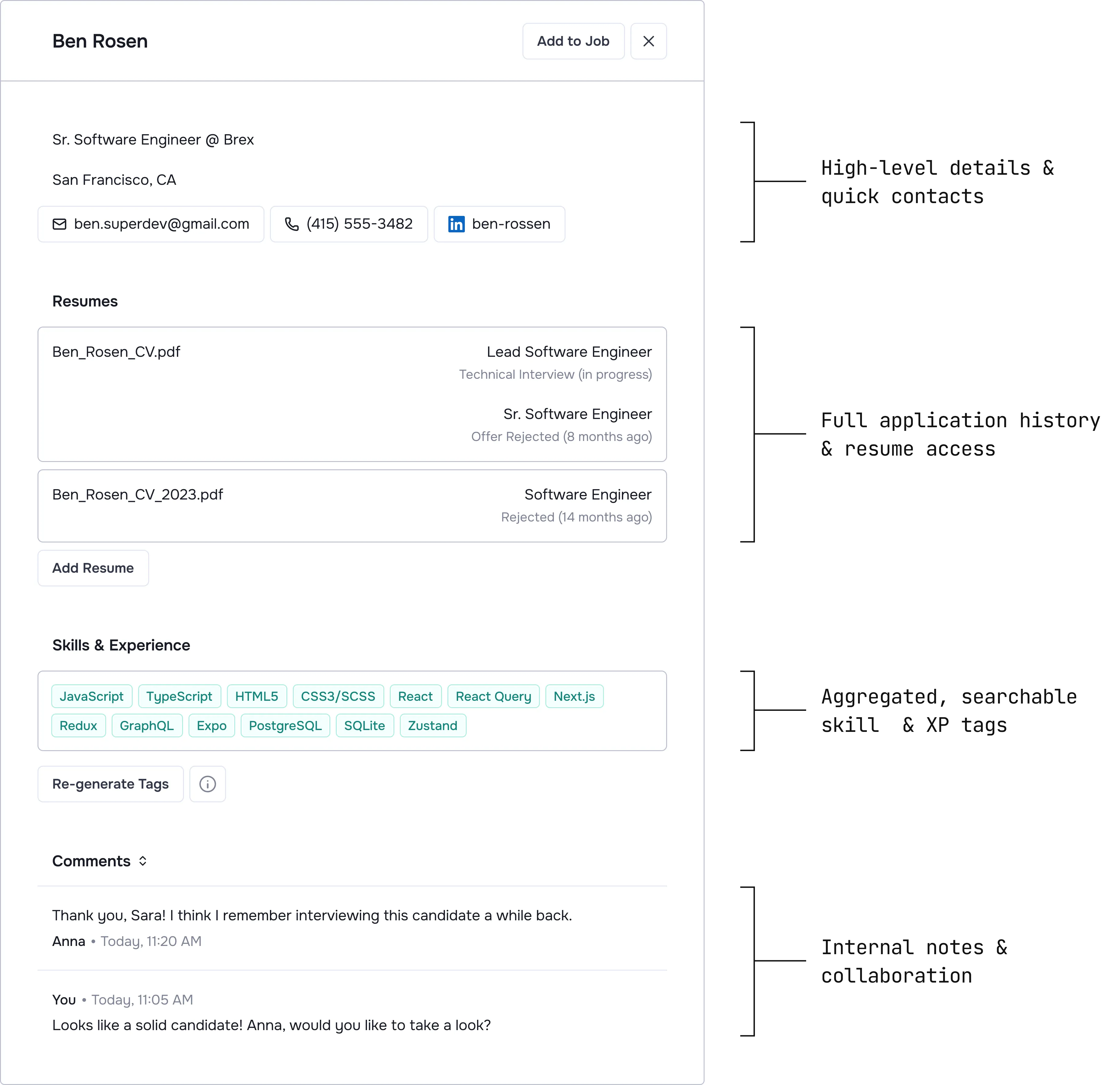
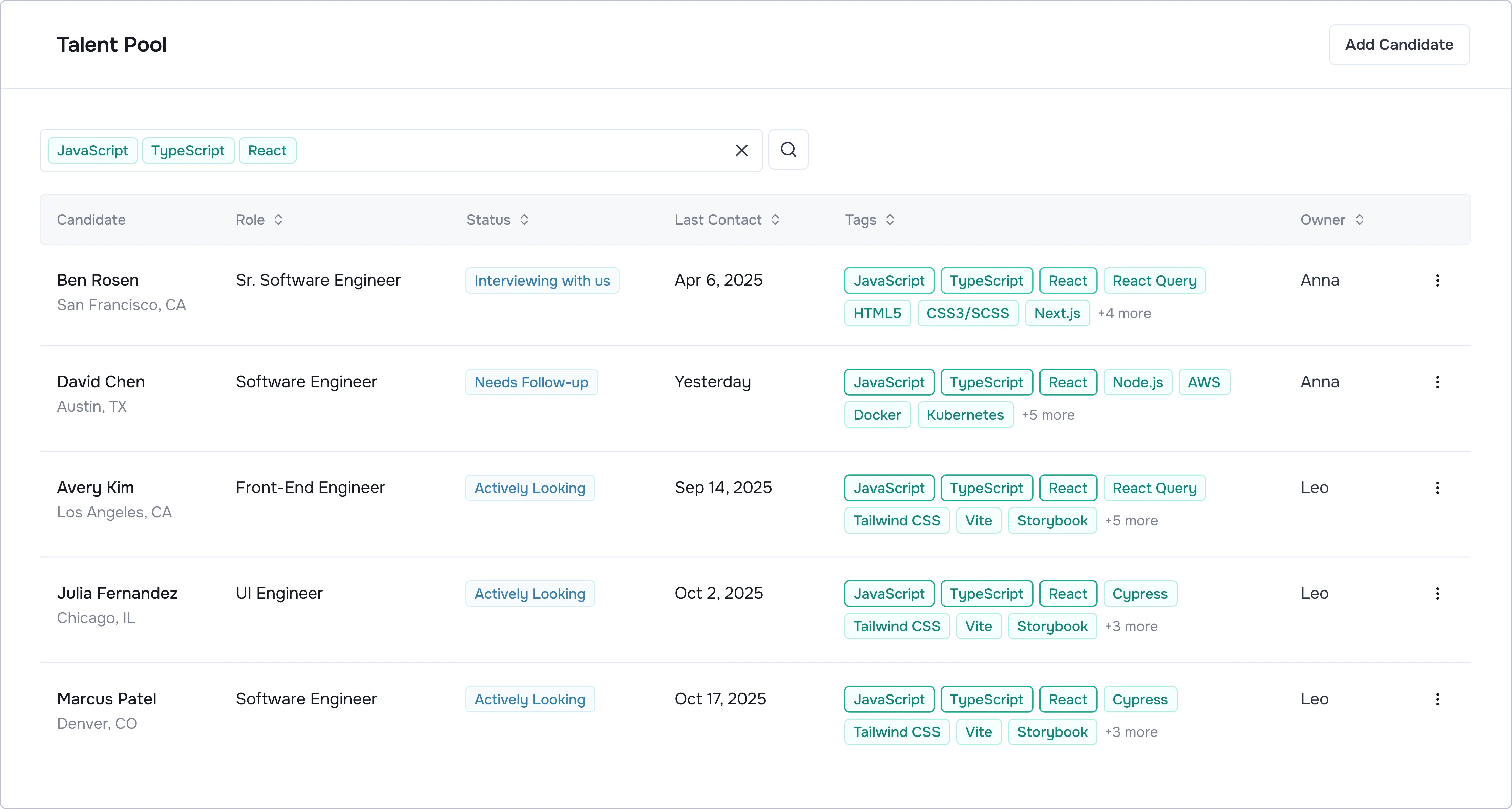
Single source of truth: Recruiters need the full history to make decisions.
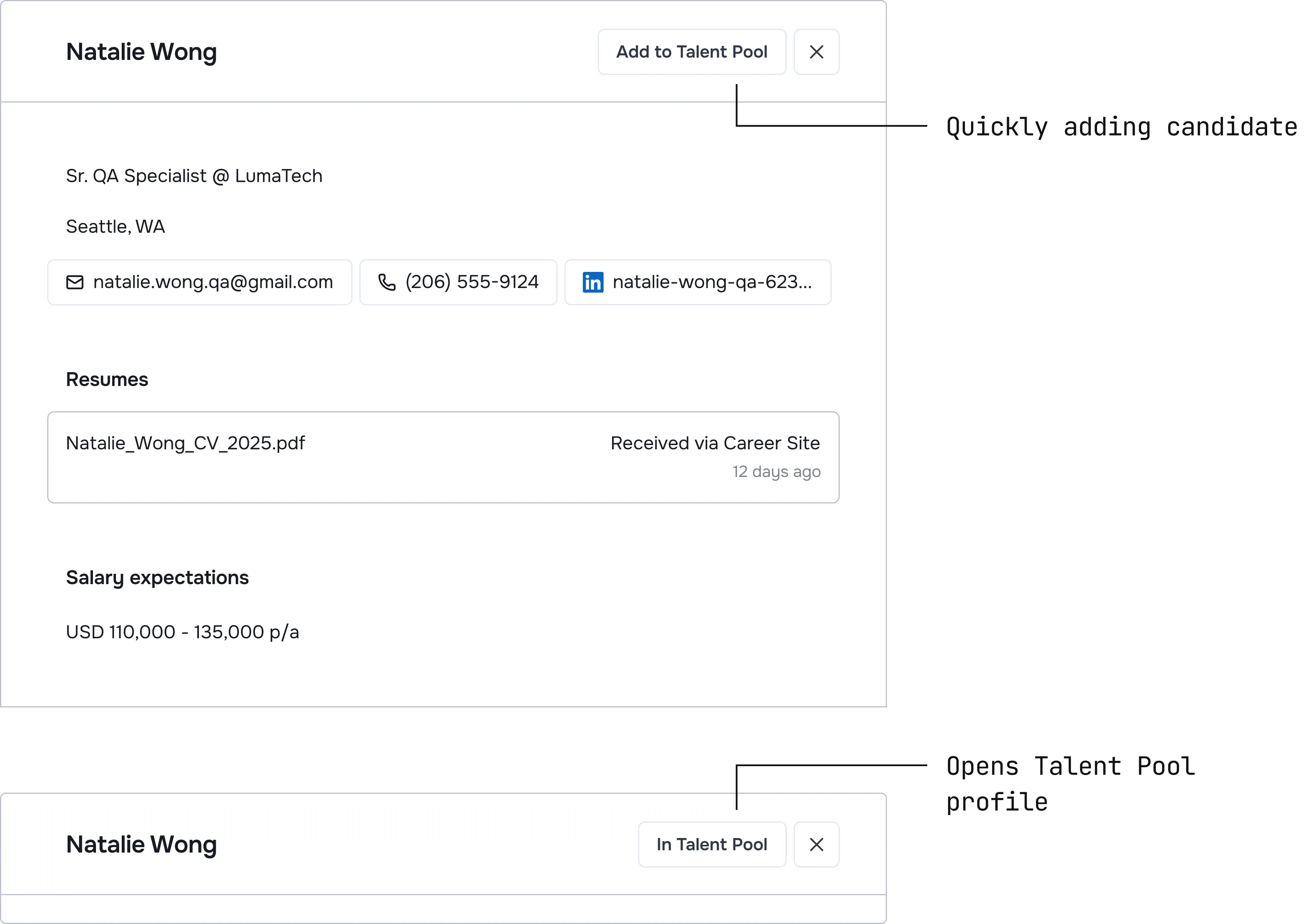
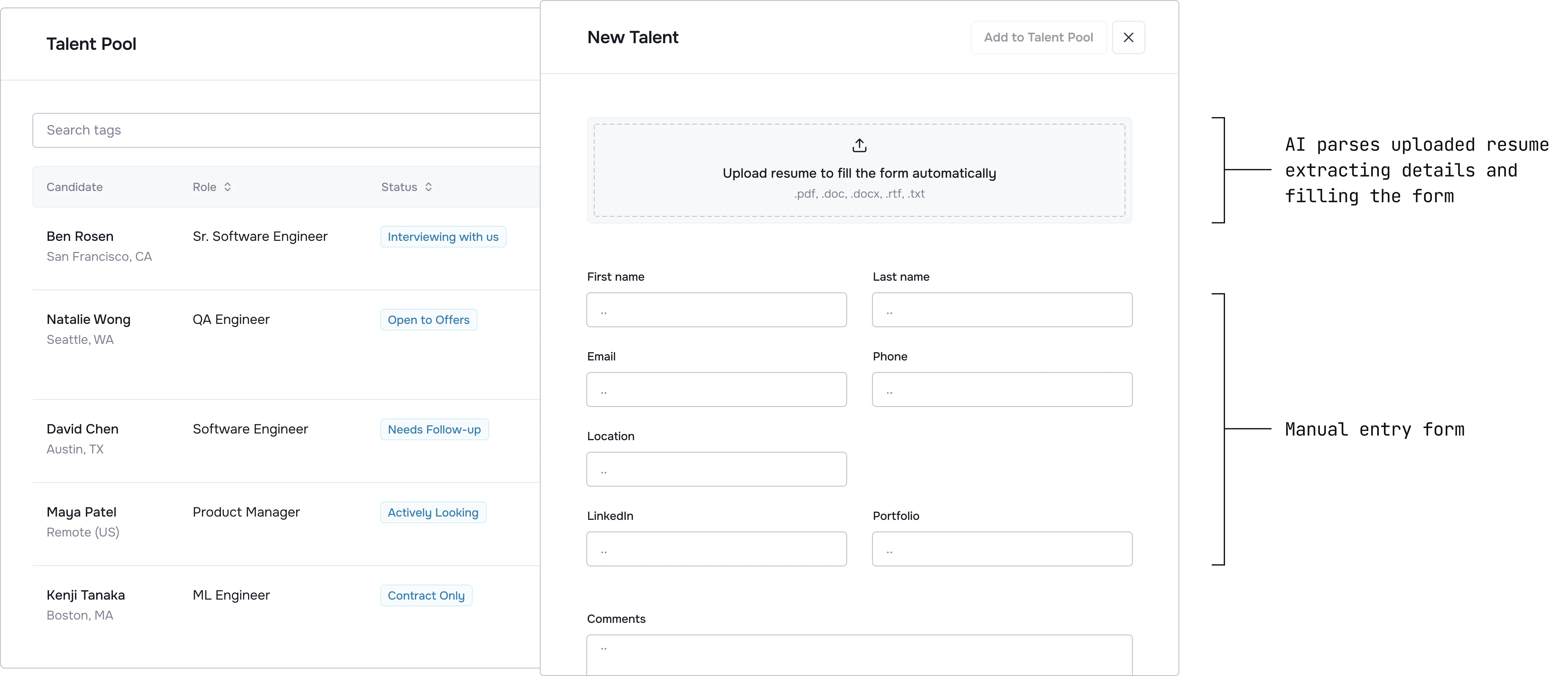
Effortless entry: If it takes more than one click, they won't use it.
Clean database: Automatic deduplication builds trust.
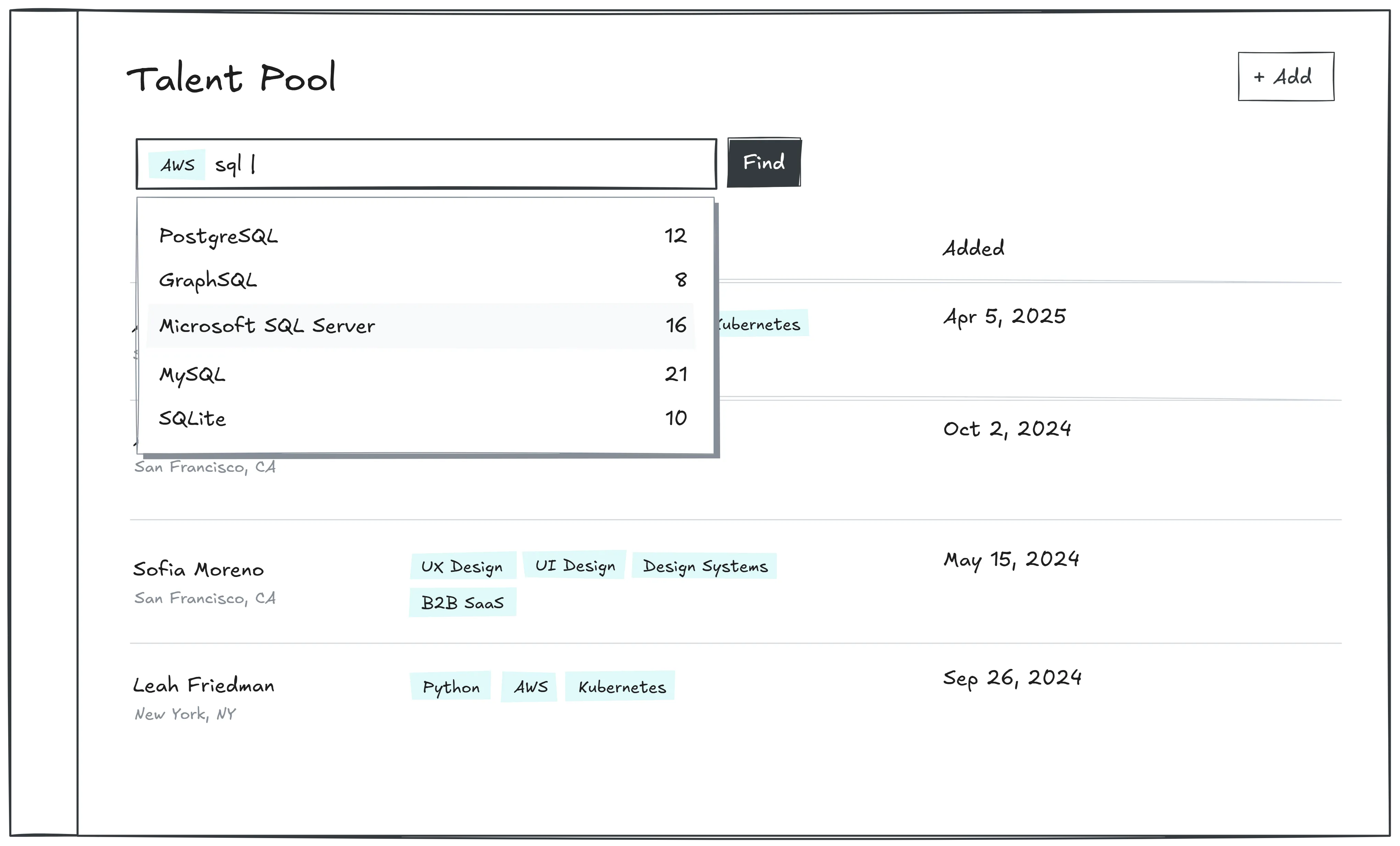
Easy search: It must be faster than their Excel sheet.
Personalized outreach: Bulk emailing sleeping candidates converts them.
Proactive matching: The system should suggest candidates before the recruiter searches.
We needed to find the absolute minimum scope that delivered value on day one. To validate our assumptions, I talked to our design partners showing them lo-fi sketches.
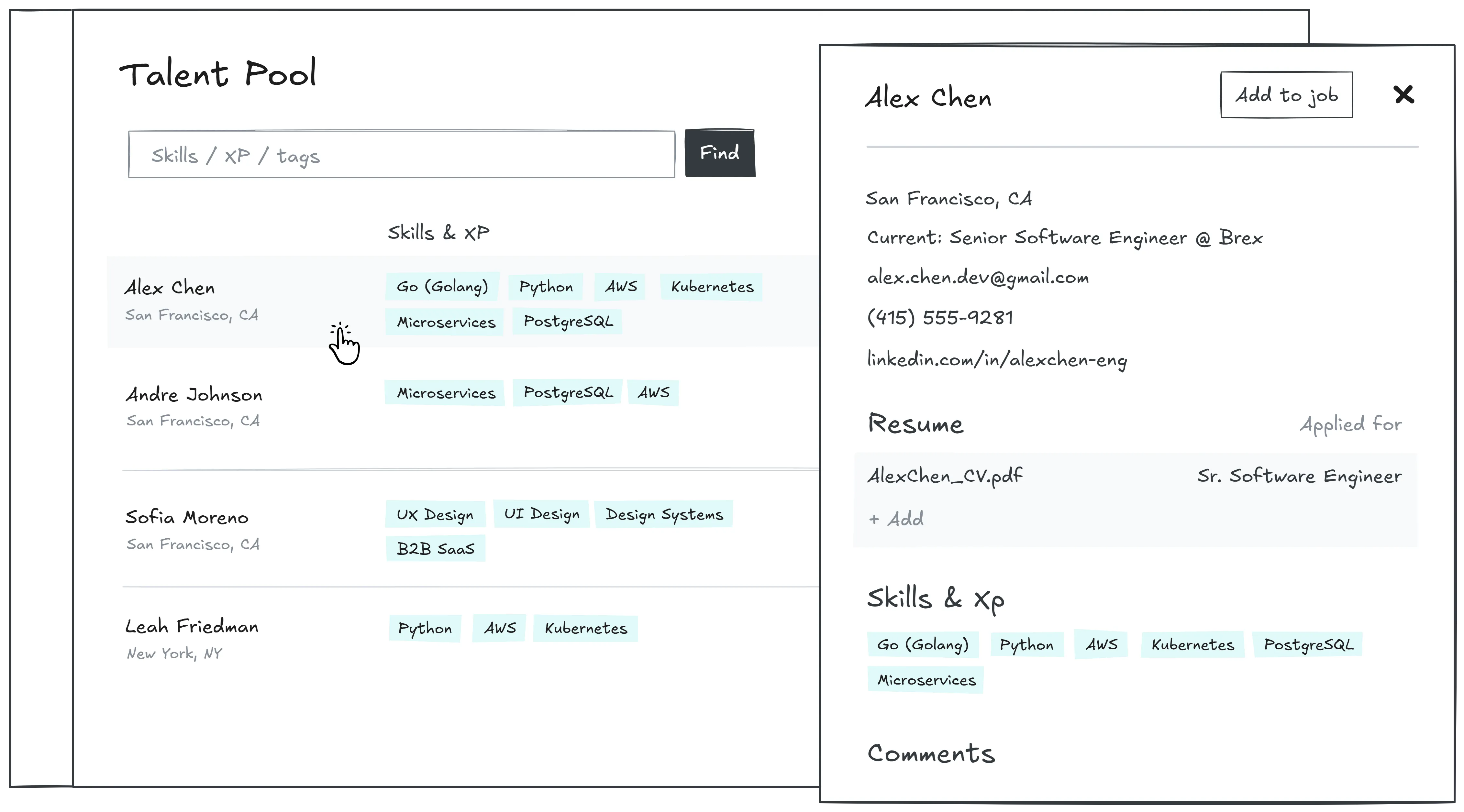
The feedback revealed a clear hierarchy of needs. While features like 'Proactive matching' and 'Outreach' were exciting, they were classified as luxuries. The immediate pain was simply access.
Recruiters confirmed they were willing to tolerate duplicates in the short term if it meant they could stop using spreadsheets.
I sat down with our Lead Engineer to review the scope against this feedback. We identified that building the "Perfect Deduplication" logic was a massive technical risk that would delay shipping by weeks. Since users had explicitly given us permission to be imperfect here, we made a joint decision to cut it.
We agreed to accept the technical debt of a 'dirty database' in exchange for the speed of delivery, locking the V1 scope to three essentials:
Single source of truth: Recruiters need the full history to make decisions.
Effortless entry: If it takes more than one click, they won't use it.
Easy search: It must be faster than their Excel sheet.